第三章 统计数据的整理和显示
第三节 数值型数据的整理与显示
(二)组距分组。当连续变量或变量值较多的情况下,可采用组距分组。
1. 概念:组距分组就是将全部变量值一次划分为若干个区间,并将这一区间的变量值作为一组。一个组的最小值称为下限,最大值称为上限。每个组上限和下限之间的距离称为组距。
2. 采用组距分组需要经过以下几个步骤:
第一步:确定组数。组数的确定应以能够显示数据的分布特征和规律为目的。在实际分组中,可以按 Sturges 提出的经验公式来确定组数K : K=1+lgn/lg2
式中 n 为数据的个数,对结果用四舍五入的办法取整数即为组数。
第二步:确定各组的组距。组距=(最大值-最小值)÷ 组数。
第三步:根据分组整理成频数分布表。比如对上面的数据进行分组,可得到下面的频数分布表,见下表。
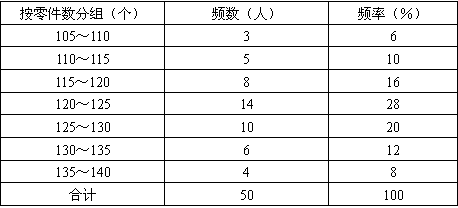
表3-4
3.“不重不漏”原则。采用组距分组时,一定要遵循“不重不漏”的原则。“不重”是指一项数据只能分在其中的某一组,不能在其他组中重复出现“不漏”是指在所分的全部组别中每项数据都能分在其中的某一组,不能遗漏。为解决“不重”的问题,统计分组时习惯上规定“上组限不在内”,即当相邻两组的上下限重叠时,恰好等于某一组上限的变量值不算在本组内,而算在下一组内。对于离散变量可以采用相邻两组组限间断的办法解决“不重”的问题。例如,对例 3-2 的数据做如下的分组,见下表。
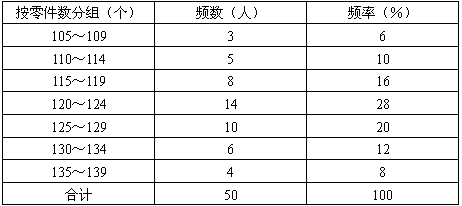
表3-5
对于连续变量可以采取相邻两组组限重叠的方法,根据“上组限不在内”的规定解决“不重”的问题,也可以对一个组的上限值采用小数点的形式,小数点的位数根据所要求的精度具体确定。例如,对零件尺寸可以分组为 10-11.99,12-13.99,14-15.99, 等等。
 您现在的位置 | 步进教学 | 第三章 | 第三节 | 第2页 (共6页)
您现在的位置 | 步进教学 | 第三章 | 第三节 | 第2页 (共6页)
